
联系方式
more本类最新英语论文
- 2024-03-31卡森•麦卡勒斯小说中..
- 2024-03-28美国黑人女性心理创伤思考―..
- 2024-03-27乔治·艾略特《织工马南》中..
- 2024-03-21超越凝视:论《看不见的人》..
- 2024-03-19《哈克贝利•费恩历险..
- 2024-03-13心灵救赎之旅――从凯利的三..
- 2024-02-22文学地理学视角下的《印度之..
- 2023-05-03英、汉名词短语之形容词修饰..
- 2023-02-07目的论视域下5g―the futur..
- 2022-07-04二语英语和三语日语学习者的..
more热门文章
- 2009-03-31the comparison of family ..
- 2010-04-02英语毕业论文范文 委婉语的..
- 2011-03-17代写英语毕业论文:global ..
- 2009-04-16常用经典英语论文写作句型
- 2009-04-17apa格式 英语论文中的apa格..
- 2015-05-13英语毕业论文范文:marketin..
- 2010-07-26英语毕业论文指导
- 2009-04-21原创优秀英语教学毕业论文范..
- 2010-09-18英语跨文化交际教学硕士毕业..
- 2010-12-26“迷惘”的主题之评析《永别..
more留学论文写作指导
- 2024-03-31卡森•麦卡勒斯小说中..
- 2024-03-28美国黑人女性心理创伤思考―..
- 2024-03-27乔治·艾略特《织工马南》中..
- 2024-03-21超越凝视:论《看不见的人》..
- 2024-03-19《哈克贝利•费恩历险..
- 2024-03-13心灵救赎之旅――从凯利的三..
- 2024-02-22文学地理学视角下的《印度之..
- 2023-05-03英、汉名词短语之形容词修饰..
- 2023-02-07目的论视域下5g―the futur..
- 2022-07-04二语英语和三语日语学习者的..
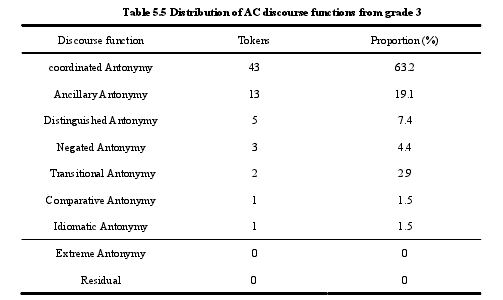
基于语料库的中国英语学习者反义词共现使用研究 [5]
论文作者:www.51lunwen.org论文属性:硕士毕业论文 thesis登出时间:2017-06-23编辑:lgg点击率:6518
论文字数:38547论文编号:org201706212057579006语种:英语 English地区:中国价格:$ 66
摘要:本文是英语毕业论文,笔者怀疑,中国的英语学习者英语反义词同现的使用是如何。反义关系是一种语义关系,可以称为一种词汇衔接,从而使语篇连贯。
nbsp;relative frequency and raw frequency are both showed, then the author calculated a ‘bias’ of each pair by dividing the higher relative frequency by the lower one. Here, the raw frequency refers to the number of occasions a certain antonymous pair appears in SWECCL 2.0 registered as token in table 5.1, and the relative frequency is the times of the pair per 100,000 words in SWECCL 2.0. The specific way to calculate the relative frequency of each pair in WECCL and SECCL is to divide the raw frequency by 12 and 10 (the amount of the total words of the two sub-corpora of SWECCL 2.0 have been introduced in chapter 4.2). For instance, in table 5.1, we find that the antonyms difficult and easy co-occur (within a span of fifteen words) on 5 occasions in the written sub-corpus WECCL and on 4 occasions in the spoken sub-corpus SECCL of the SWECCL 2.0. Through calculating, we find that the relative frequencies of difficult/easy are 0.41(0.41 times per 100,000 words) and 0.40(0.40 times per 100,000 words) respectively in WECCL and SECCL. In other words, in relative terms, this pair co-occurs at a near rate in two sub-corpora. Actually, difficult/easy is very unusual, because no matter written language or spoken one, most pairs prefer either of which. For another example, right and wrong co-occur 3.92 times per 100,000 words in WECCL and 0.40 times per 100,000 words in SECCL, leading to a bias of 9.80 (3.92 divided by 0.40) toward written language. Supposing the sub-corpora can reflect our language in general, right/wrong could be concluded to be used 9.80 times more frequent in written language, compared to spoken language.
Conclusions
This study is committed to looking into the situation of Chinese EFL learners’ use of antonym co-occurrence on the basis of corpus SWECCL 2.0, which is a rare and authoritative corpus about English spoken and written language of Chinese learners. The data of the written corpus comes from the English essays of college students along four grades not only in English majors but also in non-English majors. And the data of spoken corpus is from TEM 4 and TEM 8. The focus of the present study is to explore the discourse function distribution of antonym co-occurrence on Chinese EFL learners, which is &nb本论文由英语论文网提供整理,提供论文代写,英语论文代写,代写论文,代写英语论文,代写留学生论文,代写英文论文,留学生论文代写相关核心关键词搜索。
Conclusions
This study is committed to looking into the situation of Chinese EFL learners’ use of antonym co-occurrence on the basis of corpus SWECCL 2.0, which is a rare and authoritative corpus about English spoken and written language of Chinese learners. The data of the written corpus comes from the English essays of college students along four grades not only in English majors but also in non-English majors. And the data of spoken corpus is from TEM 4 and TEM 8. The focus of the present study is to explore the discourse function distribution of antonym co-occurrence on Chinese EFL learners, which is &nb本论文由英语论文网提供整理,提供论文代写,英语论文代写,代写论文,代写英语论文,代写留学生论文,代写英文论文,留学生论文代写相关核心关键词搜索。
 英国
英国 澳大利亚
澳大利亚 美国
美国 加拿大
加拿大 新西兰
新西兰 新加坡
新加坡 香港
香港 日本
日本 韩国
韩国 法国
法国 德国
德国 爱尔兰
爱尔兰 瑞士
瑞士 荷兰
荷兰 俄罗斯
俄罗斯 西班牙
西班牙 马来西亚
马来西亚 南非
南非






